Research
GPGPU Virtualization
Unified heterogeneous programming models simplify the development process for programmers, but resource management issues remain in multiuser systems since a user may not always have immediate access to the available resources of heterogeneous devices. System virtualization represents a good solution to improving resource utilization by providing an environment that supports the simultaneous execution of multiple guest operating systems (OSs) and supporting hardware resource management to optimally share physical resources among OSs. The CPU performance and memory virtualization have improved significantly in the past few years thanks to the support of hardware-assisted virtualization, but I/O capabilities and performance remain the weak points in system virtualization. Many difficulties are encountered when virtualizing GPU devices due to their architectures both being closed and tending to change markedly with each generation, which limits the ability of guest OSs to utilize GPU resources, especially for general-purpose computing on a GPU (GPGPU). Our aim was to build OpenCL support into a system VM and to describe and test an environment that future studies could use to share hardware resources of heterogeneous devices both fairly and efficiently.
Optimizing Compilers
Our research work has strong relations with optimizing compilers for embedded processor, e.g., microprocessing unit (MPU), digital signal processor (DSP), etc. Starting from 2003, Prof. You was involved in a research project which aimed at developing an advanced, low-power DSP prototype, which is later known as Parallel Architecture Core (PAC) DSP core. The characteristics of PAC DSP core are the novel design of the extremely distributed register file architecture and the heterogeneous five-way-issue very-long-instruction-word (VLIW) architecture. Prof. You was a key member in the compiler development team of PAC DSP with the supports of Academic Technology Development Program from Ministry of Economic Affairs (MOEA). He was in charge of developing applicable and efficient register allocation schemes incorporated with instruction scheduling and loop optimizations. Two significant techniques of register allocation methods with local and global perspectives were developed for the unique, irregular register file architecture, respectively.
Software Power Management for Embedded Systems
Power consumption has increasingly become important in computer systems. The management of power consumption while simultaneously delivering acceptable levels of performance is becoming a critical task with the proliferation of systems in several application domains such as wireless communication and embedded signal processing. In addition, it is important to manage power consumption in high-performance general purpose microarchitectures.
The focus of the research is on software techniques for application-managed power-aware computing. Thus, in this research, software will be instrumented, transformed and optimized so as to meet specified constraints in the power-performance spectrum. Consequently, the work will span the domains of algorithm-based transformations for power, optimizing compiler based techniques for power-aware computing, and variable voltage task scheduling and resource management for operation systems. Briefly speaking, this work consists of two parts: low power compiler and power-aware operating system. The following figure shows the basic structure of our research.
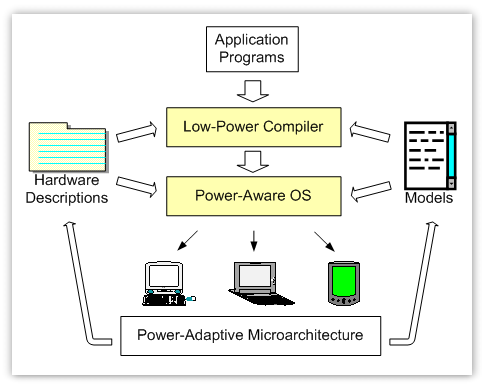
Software Enhancement for Multicore Architectures
Moore's Law continues today and can be expected to deliver increasing transistor densities for at least several more generations. However, in recent years, frequency ramping has faced mounting obstacles. Power consumption and heat generation rise exponentially with clock frequency. Until recently, this was not a problem, since neither had risen to significant levels. Now both have become limiting factors in processor and system designs. The industry's answer to today's performance challenges is to take advantage of ongoing increases in transistor density (i.e. Moore's Law) to integrate more execution cores into each processor. With multiple cores executing simultaneously, processor designers can turn down clock frequencies to contain power consumption and heat generation, while still delivering increases in total throughput for multi-threaded software.
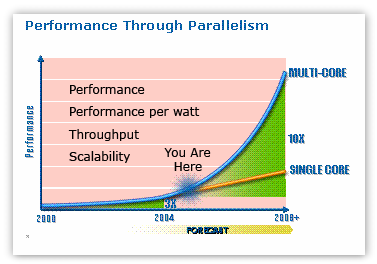
However, multi-core system is a great challenge to software development, where designers manage to assign tasks to processors to achieve the maximum perfomance. A well-stablished set of development software can benifits the multi-core software development. The goal of this research is to investigate research issues and challenges ahead for multi-core environments from viewpoints of programming models, languages, and compilers. We are on going to enhance software performance/energy consumption for multicore architectures.